深度強(qiáng)化學(xué)習(xí):游戲AI的革命性引擎
深度強(qiáng)化學(xué)習(xí)(Deep Reinforcement Learning, DRL)是人工智能領(lǐng)域近年來最具突破性的技術(shù)之一,它結(jié)合了深度學(xué)習(xí)的感知能力與強(qiáng)化學(xué)習(xí)的決策能力。在游戲領(lǐng)域,DRL已從實驗室走向?qū)嶋H應(yīng)用,成為驅(qū)動下一代游戲AI的核心技術(shù)。從經(jīng)典的雅達(dá)利游戲到復(fù)雜的即時戰(zhàn)略游戲《星際爭霸II》,DRL智能體通過與環(huán)境持續(xù)交互、試錯學(xué)習(xí),最終達(dá)到了超越人類頂級選手的水平。這種“從零開始”的學(xué)習(xí)范式,不僅展示了AI的巨大潛力,也為游戲開發(fā)帶來了全新的可能性——創(chuàng)建出更具適應(yīng)性、挑戰(zhàn)性和真實感的非玩家角色。
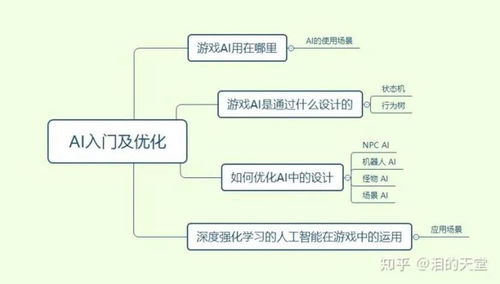
游戲AI入門:從傳統(tǒng)方法到智能體學(xué)習(xí)
對于希望將AI引入游戲的開發(fā)者而言,理解技術(shù)演進(jìn)路徑至關(guān)重要。
1. 傳統(tǒng)游戲AI技術(shù)
- 有限狀態(tài)機(jī)(FSM):最基礎(chǔ)、最廣泛使用的技術(shù),通過預(yù)定義的狀態(tài)和轉(zhuǎn)換規(guī)則控制NPC行為。優(yōu)點是簡單、直觀、可預(yù)測,但缺乏靈活性和適應(yīng)性。
- 行為樹(Behavior Tree):通過樹狀結(jié)構(gòu)組織決策邏輯,支持更復(fù)雜的分層和模塊化設(shè)計,提高了可維護(hù)性和復(fù)用性。
- 尋路算法:如A*算法,用于解決NPC在游戲世界中的移動路徑規(guī)劃問題。
2. 現(xiàn)代學(xué)習(xí)型AI入門
從傳統(tǒng)腳本式AI轉(zhuǎn)向?qū)W習(xí)型AI,第一步是建立正確的思維框架:
- 智能體(Agent):您控制的AI實體。
- 環(huán)境(Environment):游戲世界,智能體于此交互。
- 狀態(tài)(State):環(huán)境在某一時刻的描述。
- 動作(Action):智能體可以執(zhí)行的操作。
- 獎勵(Reward):環(huán)境對智能體動作的反饋信號,是驅(qū)動學(xué)習(xí)的“指南針”。
入門實踐建議從簡單的環(huán)境開始,例如OpenAI Gym中的經(jīng)典控制問題(如CartPole),或使用專為游戲AI設(shè)計的平臺,如Unity的ML-Agents Toolkit或Google的Dopamine。關(guān)鍵是在一個定義清晰、獎勵信號明確的小規(guī)模環(huán)境中,成功訓(xùn)練出第一個能完成基本任務(wù)的智能體。
AI優(yōu)化指南:提升性能與體驗的關(guān)鍵策略
一個成功的游戲AI不僅要“聰明”,更要高效、穩(wěn)定且符合游戲設(shè)計目標(biāo)。
1. 算法與模型優(yōu)化
- 獎勵塑形(Reward Shaping):設(shè)計中間獎勵引導(dǎo)智能體學(xué)習(xí),避免稀疏獎勵導(dǎo)致的難以學(xué)習(xí)問題。這是DRL應(yīng)用中最具“藝術(shù)性”的一環(huán),需要緊密結(jié)合游戲邏輯。
- 課程學(xué)習(xí)(Curriculum Learning):讓智能體從簡單任務(wù)開始,逐步增加難度,如同人類的學(xué)習(xí)過程,能顯著加速訓(xùn)練并提高最終性能。
- 集成與蒸餾:可以訓(xùn)練多個智能體(集成),或?qū)⒋竽P偷闹R“蒸餾”到小模型中,在保持性能的同時降低運行時計算開銷。
2. 工程與實踐優(yōu)化
- 并行化采樣:利用多個環(huán)境實例同時收集數(shù)據(jù),極大提高數(shù)據(jù)效率,縮短訓(xùn)練時間。
- 模型輕量化:針對部署平臺(如手機(jī)、主機(jī))優(yōu)化神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),使用量化、剪枝等技術(shù)減小模型體積和延遲。
- 人機(jī)回環(huán)(Human-in-the-loop):在訓(xùn)練中引入人類示范或反饋,可以更快地校正智能體的不良行為,使其更符合設(shè)計意圖。
3. 設(shè)計層優(yōu)化:好AI ≠ 最強(qiáng)AI
- 可控的挑戰(zhàn)性:AI的水平應(yīng)可動態(tài)調(diào)整,匹配不同玩家的技能,提供“心流”體驗。
- 行為多樣性:避免模式化,通過引入隨機(jī)性或多策略學(xué)習(xí),使AI行為難以預(yù)測,增加游戲復(fù)玩價值。
- 表現(xiàn)力與“欺騙”:有時需要讓AI表現(xiàn)出擬人化的弱點或做出看似“愚蠢”但能提升玩家樂趣的決策。
人工智能基礎(chǔ)軟件開發(fā):構(gòu)建您的AI工具箱
開發(fā)游戲AI不僅需要算法知識,還需要強(qiáng)大的軟件工程能力來構(gòu)建支撐系統(tǒng)。
1. 核心開發(fā)框架與工具鏈
- 深度學(xué)習(xí)框架:PyTorch和TensorFlow是兩大主流選擇。PyTorch動態(tài)圖特性使其在研究和原型開發(fā)中更靈活;TensorFlow則在生產(chǎn)部署和移動端支持上有其優(yōu)勢。
- 強(qiáng)化學(xué)習(xí)庫:Stable Baselines3, Ray RLlib等高級庫封裝了PPO、DQN等經(jīng)典算法,讓開發(fā)者能更專注于問題本身而非算法實現(xiàn)細(xì)節(jié)。
- 游戲AI專用平臺:
- Unity ML-Agents:允許在Unity引擎中直接訓(xùn)練智能體,無縫集成到游戲開發(fā)流程。
- Godot Engine:開源引擎,其AI相關(guān)生態(tài)也在快速發(fā)展。
2. 系統(tǒng)架構(gòu)設(shè)計要點
- 訓(xùn)練與推理分離:訓(xùn)練系統(tǒng)(通常使用Python)追求靈活與高效,而部署在游戲內(nèi)的推理系統(tǒng)(可能用C++/C#)必須追求極致的性能和穩(wěn)定性。兩者通過模型文件(如ONNX格式)銜接。
- 模擬環(huán)境構(gòu)建:創(chuàng)建一個與真實游戲高度一致、但運行速度可能快數(shù)十甚至數(shù)百倍的“模擬器”用于訓(xùn)練,是加速迭代的關(guān)鍵。
- 可觀測性與調(diào)試工具:開發(fā)可視化工具來監(jiān)控智能體的內(nèi)部狀態(tài)(如價值函數(shù)、注意力分布)、決策過程和訓(xùn)練曲線,這對于調(diào)試復(fù)雜AI行為不可或缺。
3. 邁向生產(chǎn)環(huán)境
- 版本控制:不僅控制代碼,也要對模型、超參數(shù)、訓(xùn)練數(shù)據(jù)和實驗結(jié)果進(jìn)行系統(tǒng)化管理(可使用DVC、MLflow等工具)。
- 持續(xù)集成/持續(xù)部署(CI/CD):自動化測試訓(xùn)練流程,確保代碼更改不會破壞現(xiàn)有功能,并能自動將訓(xùn)練好的模型部署到測試環(huán)境。
- 倫理與測試:建立對AI行為的測試規(guī)范,防止出現(xiàn)破壞游戲平衡、利用程序漏洞(“鉆空子”)或產(chǎn)生負(fù)面社會影響的行為。
未來展望
深度強(qiáng)化學(xué)習(xí)為游戲AI打開了新世界的大門,從完全自主的游戲角色到動態(tài)平衡的游戲系統(tǒng),再到個性化的游戲內(nèi)容生成,其應(yīng)用前景廣闊。技術(shù)始終是工具,成功的游戲AI永遠(yuǎn)是技術(shù)實現(xiàn)與游戲設(shè)計智慧的完美結(jié)合。對于開發(fā)者而言,踏上這段旅程意味著需要同時擁抱機(jī)器學(xué)習(xí)的前沿算法和扎實的軟件工程實踐。從一個小型實驗項目開始,逐步構(gòu)建起您對智能體、環(huán)境和獎勵函數(shù)的直覺,最終將創(chuàng)造出能夠真正豐富玩家體驗、充滿驚喜與生命力的游戲人工智能。